









Постановка задачи
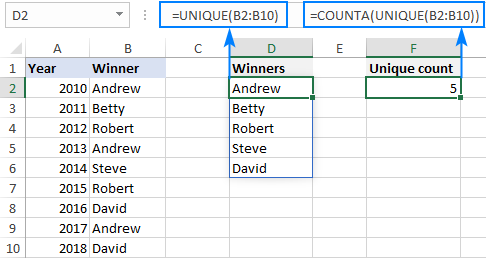
Существует диапазон данных, в котором некоторые значения повторяются более одного раза:

Задача — посчитать количество уникальных (неповторяющихся) значений в диапазоне. В приведенном выше примере легко увидеть, что на самом деле упоминаются только четыре варианта.
Рассмотрим несколько способов ее решения.
Способ 1. Если нет пустых ячеек
Если вы уверены, что в исходном диапазоне данных нет пустых ячеек, вы можете использовать короткую и элегантную формулу массива:

Не забудьте ввести его как формулу массива, т.е. нажать после ввода формулы не Enter, а комбинацию Ctrl+Shift+Enter.
Технически эта формула перебирает все ячейки массива и вычисляет для каждого элемента количество его вхождений в диапазон с помощью функции COUNTIF (СЧЁТЕСЛИ). Если представить это как дополнительный столбец, то это будет выглядеть так:

Затем вычисляются дроби 1/Количество случаев для каждого элемента и все они суммируются, что даст нам количество уникальных элементов:

Способ 2. Если есть пустые ячейки
Если в диапазоне есть пустые ячейки, то придется немного улучшить формулу, добавив проверку на пустые ячейки (иначе мы получим ошибку деления на 0 в дроби):

Вот и все.
- Как извлечь уникальные элементы из диапазона и удалить дубликаты
- Как выделить дубликаты в списке цветом
- Как сравнить два диапазона на наличие дубликатов
- Извлечение уникальных записей из таблицы по заданному столбцу с помощью дополнения PLEX